

HANA News Blog
Buchtipp: SAP HANA Deepdive: Optimierung und Stabilität im Betrieb
Jens Gleichmann und Matthias Sander • 30. März 2025
Unser erstes Buch ist nun verfügbar

Pünktlich zu den DSAG Technologietagen 2025 wurde unser erstes Buchprojekt finalisiert und gedruckt. Hierbei handelt es sich
nicht um das x-te HANA Administrationsbuch mit dem nötigen Basiswissen rund um die HANA Datenbank, sondern um eines das auf diesen Büchern für einen echten Deepdive aufbaut. Aktuell ist das Buch lediglich in Deutsch verfügbar.
Was steckt alles im Buch?
- - knapp 300 Seiten HANA Know-How
- - ~49543 Wörter
- - 324.960 Zeichen (ohne Leerzeichen) / 372.544 Zeichen (mit Leerzeichen)
- - 3298 Absätze
- - 8270 Zeilen
- - 11 Kapitel geballte Erfahrung, welche man nicht in Guides oder Dokumentationen findet
- - 158 Bilder - alle eigens angefertigt (besonderes Dankeschön an Dominik Fiedler!)
- - viel Zeit (über 250h), akribische Arbeit, Schweiß, Researching und ein paar graue Haare mehr
Wer sollte das Buch lesen?
- - erfahrene SAP Admins
- - HANA DBAs mit dem Drang nach Expertise
- - SAP Architekten für Themen wie Wartung und Sizing
- - SAP / HANA Entwickler mit dem Interesse Abfragen performant zu gestalten
Inhaltsverzeichnis:
- 1. SQL-Skriptsammlung
- 2. HANA System Sizing
- 3. Maintenance
- 4. Parametrisierung
- 5. Workload Management
- 6. Optimizer
- 7. Partitionierung
- 8. Hints
- 9. Index
- 10. Troubleshooting
- 11 Tools zu Analysezwecken
Wo bekommt Ihr es?
- - espresso-tutorials.com (via digitales Abo oder als gebundenes Buch)
- - sprecht uns an
- - ISBN: 9783960123675
Ein riesiges Dankeschön an die vielen Kollegen und Experten für die Unterstützung, Überprüfung und Feinjustierung.
SAP HANA News by XLC

Please notice that when you want to run HANA 2.0 SPS07, you need defined OS levels. As you can see RHEL7 and SLES12 are not certified for SPS07. The SPS07 release of HANA is the basis for the S/4HANA release 2023 which is my recommended go-to release for the next years. Keep in mind that you have to go to SPS07 when you are running SPS06 because it will run out of maintenance end of 2023.

KVM as alternative with low TCO
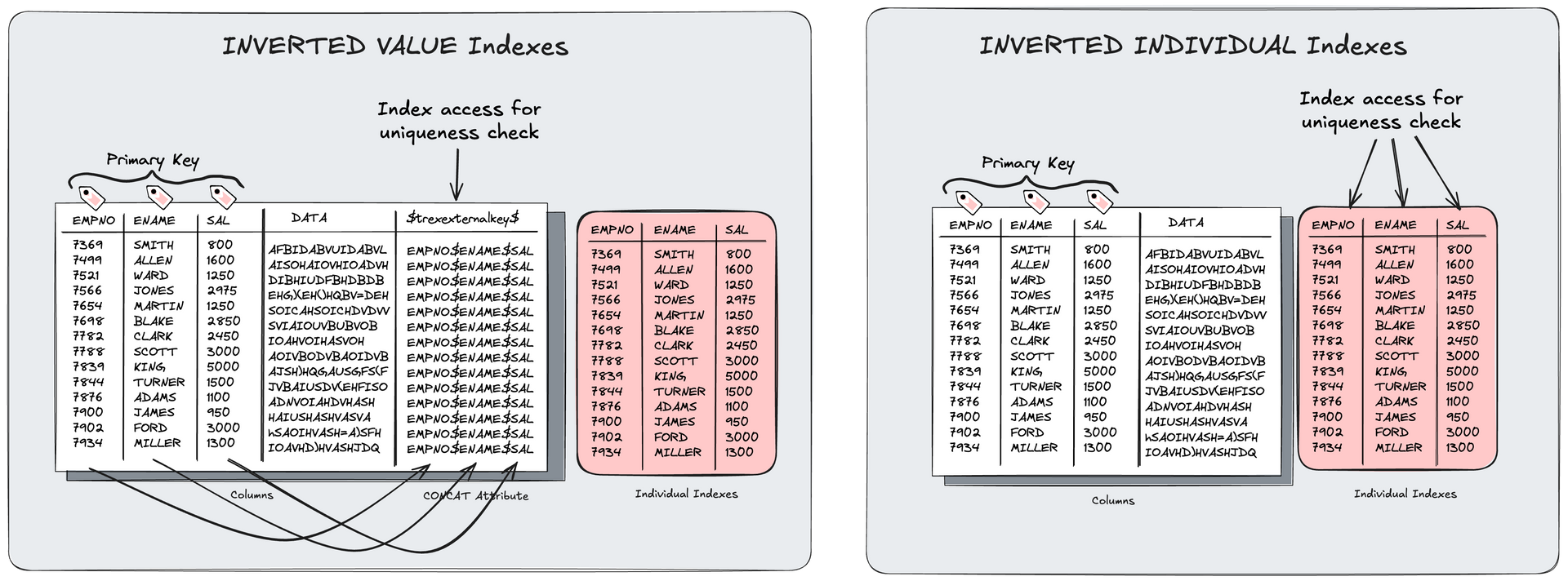
An inverted individual index is a special type of SAP HANA index which can only cover unique indexes. This includes all primary key structures. Unlike traditional column store indexes on more than one column (inverted value, inverted hash) an inverted individual index (Inv Idv Idx) doesn't need a dedicated concat.
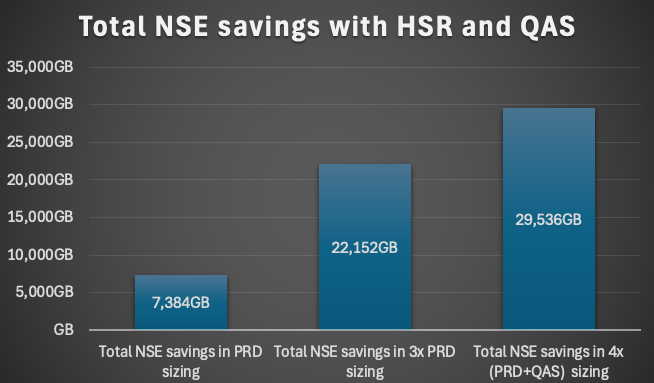
This blog presents the results of a customer case which can be used as a reference for other implementations
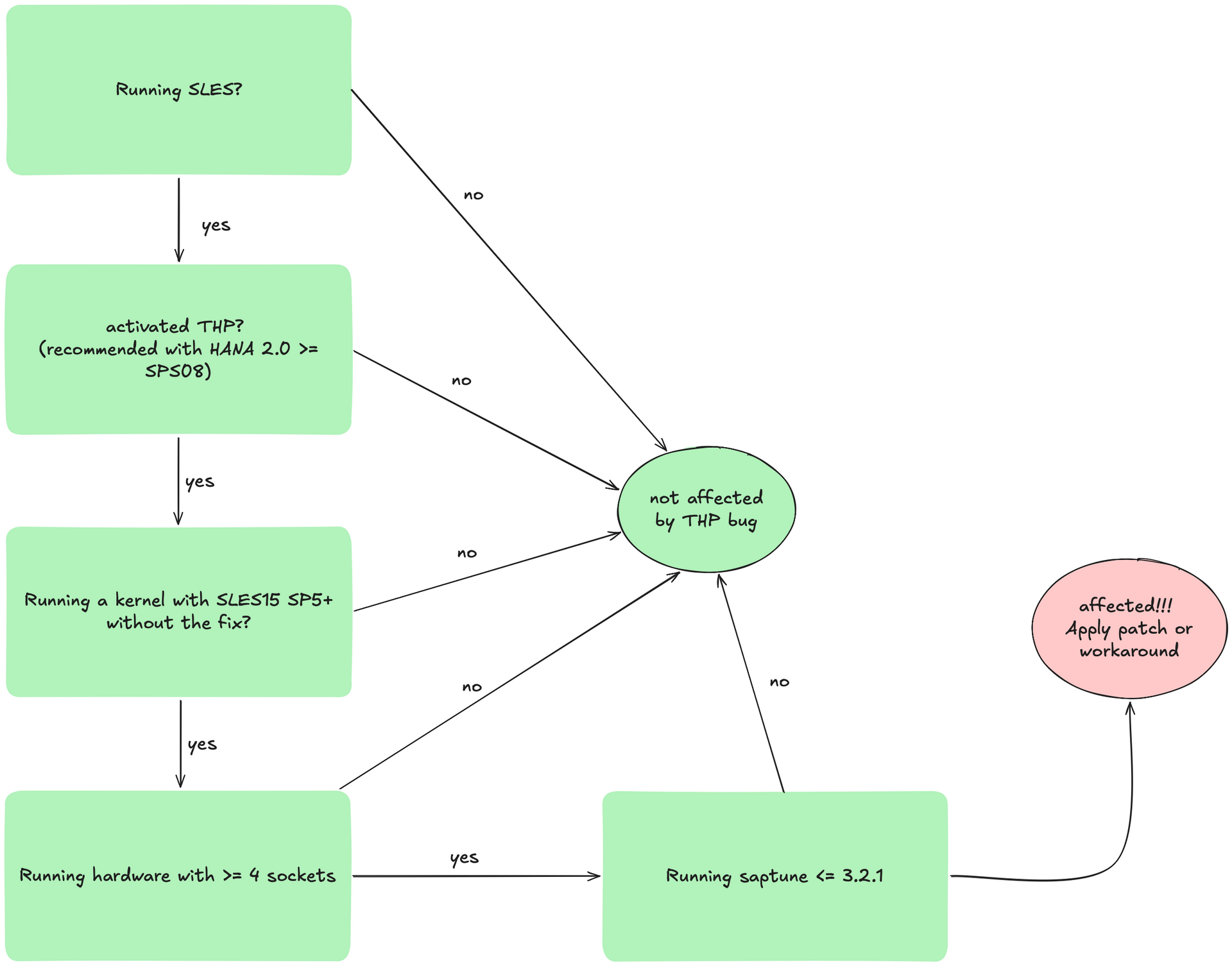
SAP HANA systems may experience high swap usage, hangs, or performance issues when THP (Transparent Huge Pages) is enabled with "madvise". This occurs on multi-NUMA node systems where one or more NUMA nodes are close to full memory usage while others have plenty of free memory, and counters for THP allocations, direct
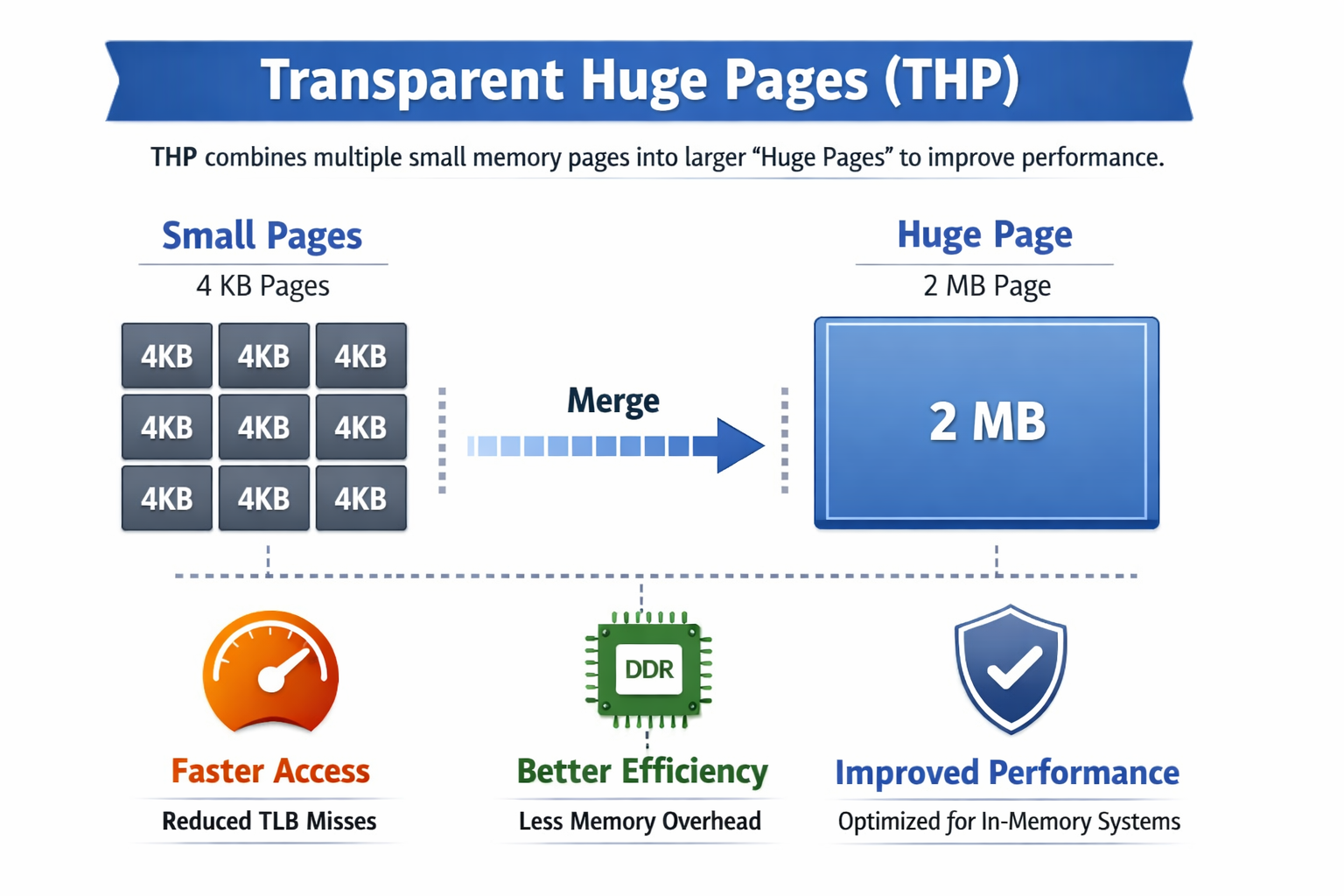
Transparent Huge Pages (THP) with madvise can trigger high swap usage, performance issues, or even system hangs on multi-NUMA systems.

With SPS06 and even stronger in SPS07 the HEX engine was pushed to be used more often. This results on the one hand side in easy scenario to perfect results with lower memory and CPU consumption ending up in faster response times. But in scenarios with FAE (for all entries) together with FDA (fast data access), it can result in bad performance. After some customers upgraded their first systems to SPS07 I recommended to wait for Rev. 73/74. But some started early with Rev. 71/72 and we had to troubleshoot many statement. If you have similar performance issues after the upgrade to SPS07 feel free to contact us! Our current recommendation is to use Rev. 74 with some workarounds. The performance degradation is extreme in systems like EWM and BW with high analytical workload.
SAP NSE was introduced with HANA 2.0 SPS04 and based on a similar approach like data aging. Data aging based on a application level approach which has a side effect if you are using a lot of Z-coding. You have to use special BADI's to access the correct data. This means you have to adapt your coding if you are using it for Z-tables or using not SAP standard functions for accessing the data in your Z-coding. In this blog we will talk about the technical aspects in more detail.
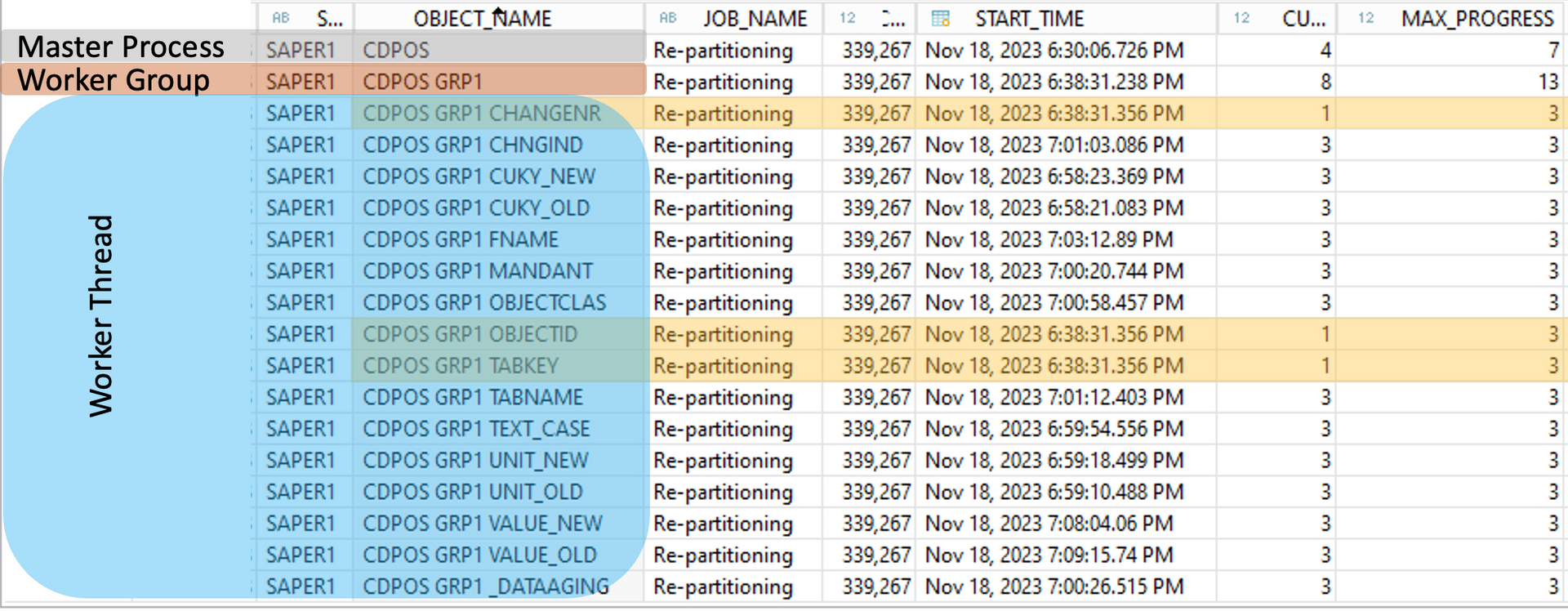
SAP HANA scaling and tuning with proper partitioning designs

In transformation projects like SAP RISE / SAP Cloud ERP, the Roles & Responsibilities (R+R) list often serves as the backbone for collaboration between customer, partner, and SAP. Yet too often, this list is treated as a static document rather than a living framework. Sometimes nobody knows exactly what was defined by