HANA News Blog
SAP HANA data statistics for the optimizer
Popular misconcept: HANA needs no statistics
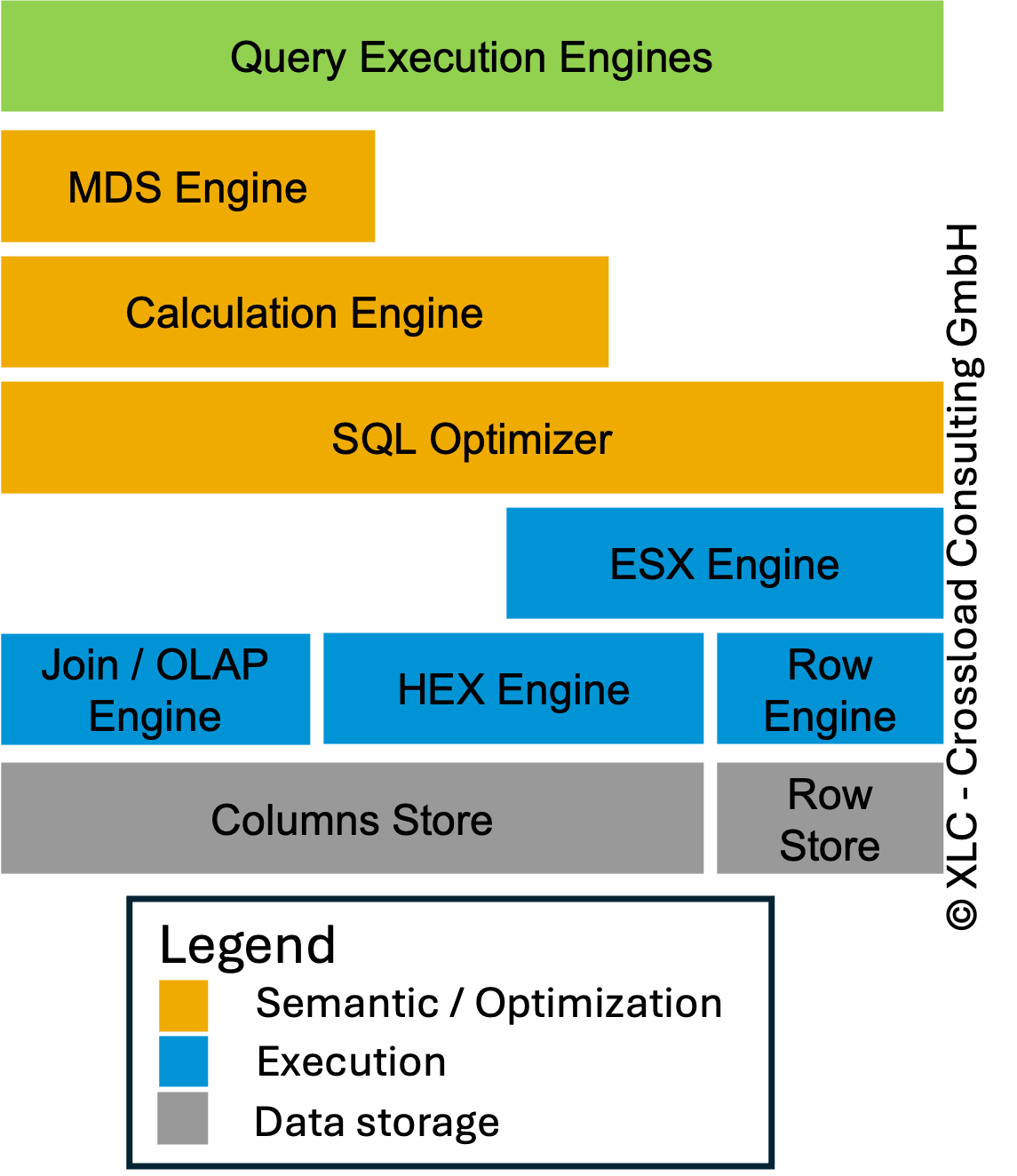
In the world of modern database management systems, query performance is not just a matter of hardware—it’s about smart execution plans. At the core of generating these plans lies a critical component: optimizer statistics. Every DBA is aware of the optimizer data statistics. Without this details the optimizer can only generate wrong execution plans. There are multiple optimizer statistics depending on the database:
- system statistics (CPU, I/O, memory)
- workload statistics
- noworkload statistics
- table statistics
- column statistics
- index statistics
Besides the different objects also the collect method is important. There are dynamic or runtime statistics and histograms. As always up-to-date and accurate statistics will lead to better execution plans depending on the costs. If a table is changing too frequently accurate and up-to-date statistics are not possible and would generate too heavy overhead. It must be in balance and this is depending on the different workloads.
Accurate statistics help the optimizer decide on:
- Join order
- Join method (e.g., hash join vs. nested loop)
- Index usage
- Degree of parallelism
Poor decisions can lead to excessive memory usage and CPU spikes.
The note
2100010 - SAP HANA: Popular Misconceptions deserves an update regarding the optimizer stats. Many "experts" talk about HANA as magical database which tunes itself and needs no optimizer statistics. The truth is that also HANA relies on different statistic data to generate an optimal execution plan. For virtual/remote tables like for SDA scenarios the manual statistics are used since HANA 1.0 SPS 06. There are different types of data statistics:
| Statistics type | Source | Details | Created |
|---|---|---|---|
| HISTOGRAM | explicit | Creates a data statistics object that helps the query optimizer estimate the data distribution in a single-column data source. If you specify multiple columns in <data_sources>, then multiple data statistics objects (HISTOGRAM) are created--one per column specified. | manually |
| SAMPLE | explicit, runtime | When beneficial, the SQL optimizer generates system SAMPLE data statistics objects automatically on column and row store tables. However, this behavior can incur a cost to performance. You can avoid this cost by creating SAMPLE data statistics objects explicitly (in advance). Creating them explicitly is especially useful in situations where sampling live table data is expensive (for example, very large tables). (default: 1000 records) | automatically on column and row store tables |
| SIMPLE | explicit, runtime | Simple column statistics likemin, max, null count, count, and distinct count for a single-column data source. When beneficial, the SQL optimizer maintains system SIMPLE data statistics objects automatically on column and row store tables only. Superset of RECORD COUNT statistics | automatically on column and row store tables |
| SKETCH | explicit | Column group statistics, e.g. number of combination of values of multiple columns Useful for selectivity estimations when more than one column is evaluated | manually |
| TOPK | explicit, runtime | Column statistics including most frequent column values Mainly used for join-size estimation Superset of SIMPLE statistics | automatically on column store tables |
| RECORD_COUNT | explicit, runtime | Record count on table level | automatically on column and row store tables |
runtime: Automatic ad-hoc calculation
explicit: Manual creation via Syntax CREATE STATISTICS
For SAMPLE statistics, explicit statistics take precedence over runtime statistics.
For other statistics types, runtime statistics take precedence over explicit statistics. If you want to change this behavior, you can force the use of explicit statistics instead of runtime statistics using the following parameter: indexserver.ini -> [datastatistics] -> dev_force_use_non_runtime_datastatistics = true
Although HANA is an in-memory database not always all data is loaded into the memory. In some cases only a partition or some columns are loaded. The runtime statistics can only be created if all data is loaded. This happens during the prepare and compile phase. In some cases e.g. in the context of NSE this can take significant longer.
If the needed column is not fully loaded the data statistics are estimated. This approach eliminates column load overhead, but the data statistics estimations may be imprecise, imposing the risk that a bad execution plan is picked. The distinct count of a column is in this case set to the row count, representing a unique column. This can be far away from the real distinct count and unfavorable join orders and execution engines can be the consequence. In this case it can make sense to use manual statistics which have also to be updated frequently.
If you create data statistics manually you can choose between different refresh types:
| Refresh type | Detail |
|---|---|
| AUTO | specifies that the data statistics object is refreshed automatically when underlying data changes. AUTO is only supported on column store, extended store, and multistore tables. |
| MANUAL | specifies that the database statistics object is not refreshed until a rebuild is explicitly requested by a REFRESH STATISTICS statement. |
| DEFAULT | specifies that the database server decides the best refresh strategy based on the data source. For example, for data statistics objects on column store data sources, the database server applies AUTO for the default. |
SAP HANA News by XLC