HANA News Blog
Smart SAP HANA Optimization: Applying NSE for Better Efficiency
Optimize your HANA with NSE

- 6 tables fully transitioned to NSE
- 1 table partially transitioned (single partition)
- 1 table transitioned by specific columns
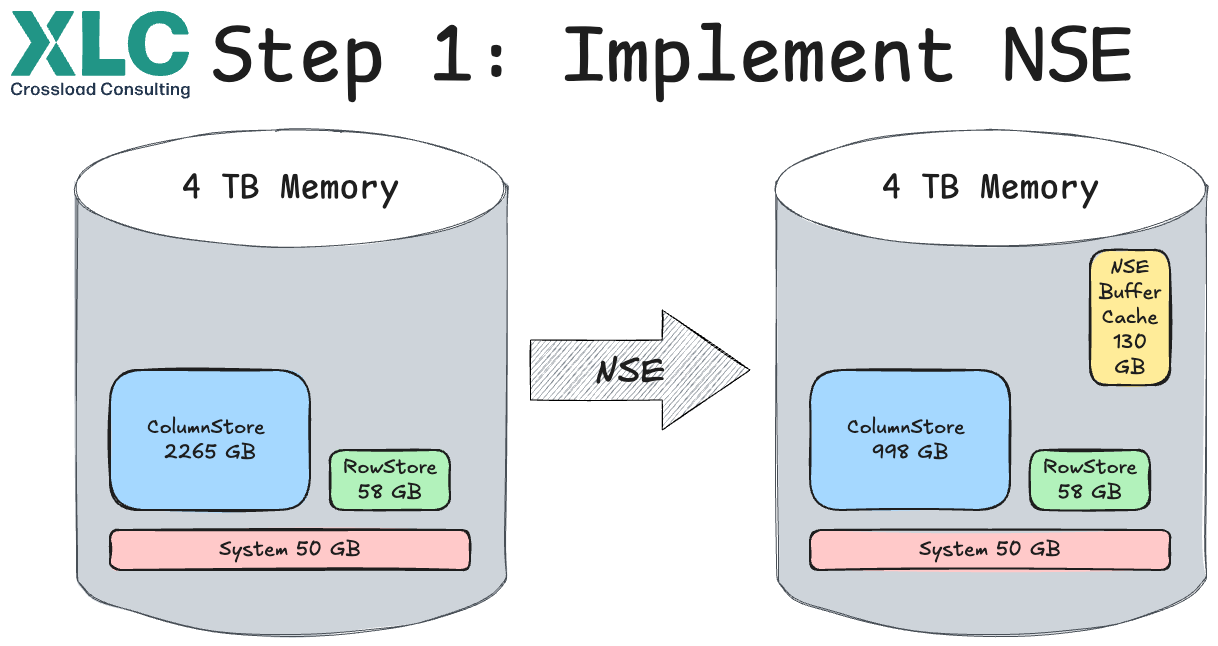
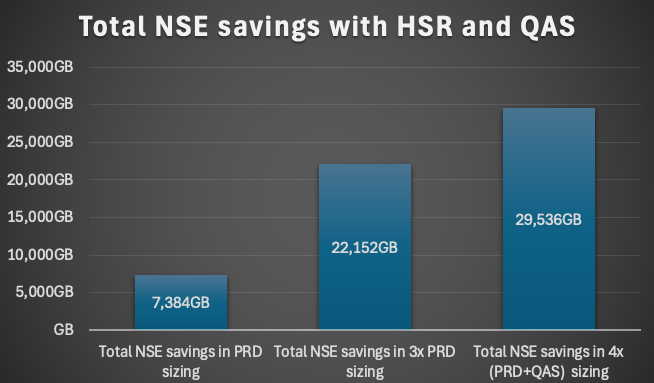
The Results: Memory Savings 1135 GB
- NSE: 945 GB saved
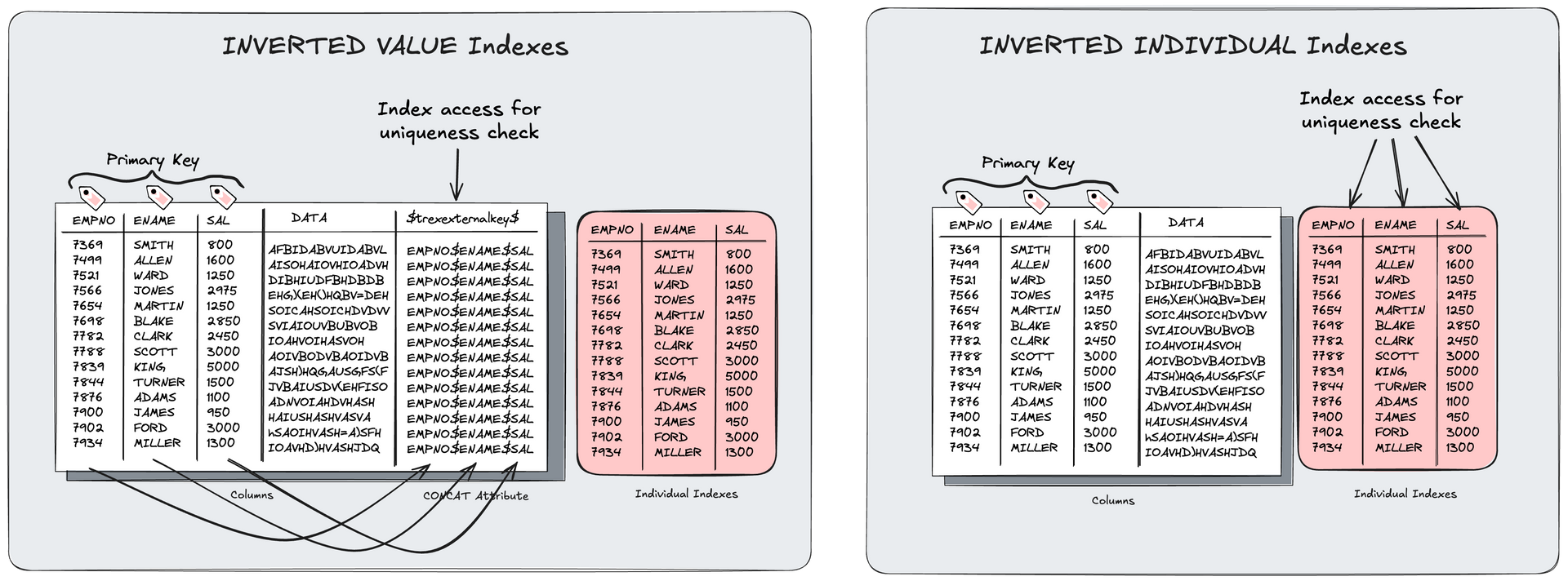
- Changing one table to Inverted Individual Index: 90 GB saved
- SBCMCONT1 cleanup: 230 GB saved
- Offset: NSE Buffer Cache (130 GB)
As you can see, we have not only saved memory through NSE, but have also discovered other potential savings in the course of the project.
Including the NSE buffer cache, we were able to save around 48% of the memory compared to the initial situation. A really great result. On average, we achieve savings of around 25-35% for an ERP system.

After the GoLive of NSE, the client waited around 5 weeks until the database memory was reduced from 4 TB to 2.5 TB, despite prior and intensive tests in the test system.
As a result, we achieved
optimal sizing according to SAP:
- 50 % payload data
- 50 % working memory
It would have been possible to reduce the memory to 2 TB, but then we would have been directly at an utilization of 62%. Depending on the growth and use of the database, this may already be too much and it would have to be increased again soon.
The customer has decided on a conservative approach and selected 2.5 TB.

Beyond NSE: Holistic Data Management Is Key
While NSE delivered exceptional results in this case, it is not the only solution for optimizing SAP HANA systems. Proactive data archiving and, importantly, data deletion can also lead to significant memory savings. For example, SAP note "2388483 - How-To: Data Management for Technical Tables" provides excellent strategies for managing technical tables effectively.
These steps — NSE, archiving, and deletion — serve as excellent preparation for:
- Purchasing new on-premise hardware
- Migrating to cloud or other cloud environments
- Transitioning to SAP RISE
The less data you store in memory, the lower your costs and environmental impact. These optimizations not only improve performance but also contribute to a greener IT landscape by reducing energy usage. It is better to clean up first and then migrate.
As you can see from this story, an NSE project helps you to get to know your data better and also reveals other areas where memory can be saved.
How Can We Help? If you’re considering memory optimization for your SAP HANA system we’re here to help. Feel free to reach out with any questions or to explore how we can assist you in unlocking the full potential of your SAP HANA environment.
Together, let’s make SAP HANA smarter, leaner, and more sustainable.
SAP HANA News by XLC