HANA News Blog
Data Tiering case study part II: Inverted Individual Indexes
Inv Idv Idx - Inverted Individual Indexes - warm data

An inverted individual index is a special type of SAP HANA index which can only cover unique indexes. This includes all primary key structures. Unlike traditional column store indexes on more than one column (inverted value, inverted hash) an inverted individual index (Inv Idv Idx) doesn't need a dedicated concat attribute.
Why Inv Idv Idx are relevant for data tiering purposes?
- Significantly reduced memory footprint due to absence of concat attribute
- Less I/O in terms of data and redo logs
- Reduced table optimization efforts
- DML change operations can be faster due to reduced concat attribute maintenance
What influence can such indexes have on the sizing?
40-50% of S/4HANA systems can consists of indexes. Mostly of the indexes are primary keys, but there are also some secondary indexes which are in the most cases not unique indexes. This means indexes have an overall impact of 30-40% on the sizing. It depends on the size of the unique indexes. This can vary for each system.
Why is it not sensible to convert every unique index?
It is possible to convert every unique index but as always it is a trade-off between savings and performance. It depends on the mixture of filter of the critical SQL workload. If the filters are part of the index and one of the columns is also very selective, it might makes no difference in terms of performance.
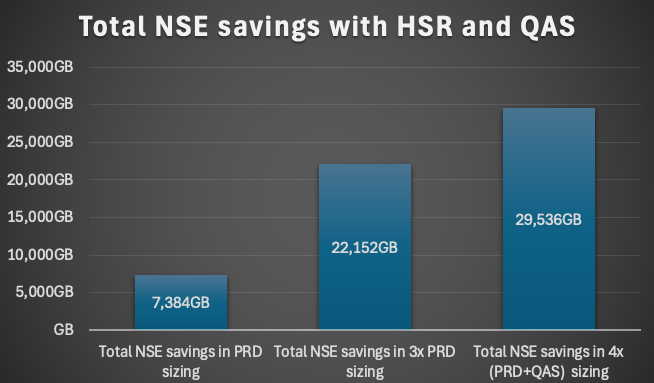
How much memory can be saved with Inv Idv Idx?
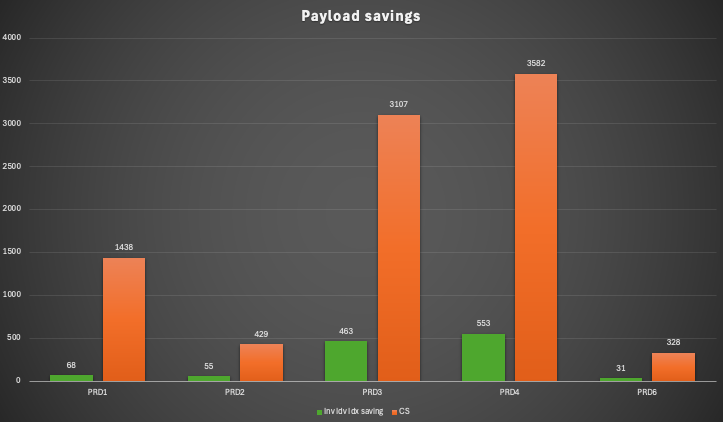
It depends on each system, the workload and the distinct values of the column of the unique indexes. But as average we observed 11% savings in the payload.
The smallest saving was 5% and the peak saving 15% of the CS payload.
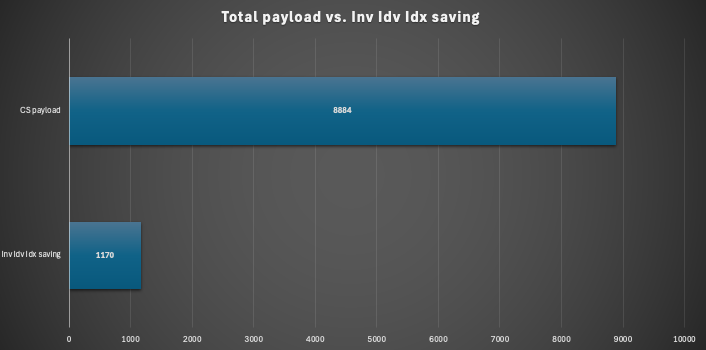
In total we could save round about 1.2TB memory out of 8.9TB which is percentage 13.5%.
For which systems the Inverted Individual Indexes can be used?
They are supported in any HANA system. The definition is possible in SE11. For BW/4HANA systems they are available in BW designer via the name “Memory-optimized Primary Key Structure”.
The good aspect on this part of data tiering is that it can be analyzed and implemented quite fast. But it must be tested well as every implementation.
If you are interested in more details, you can have a look at the general SAP Note 2600076 or our book “HANA deep dive” which will be released in a few weeks (it is already available in German).
Summary
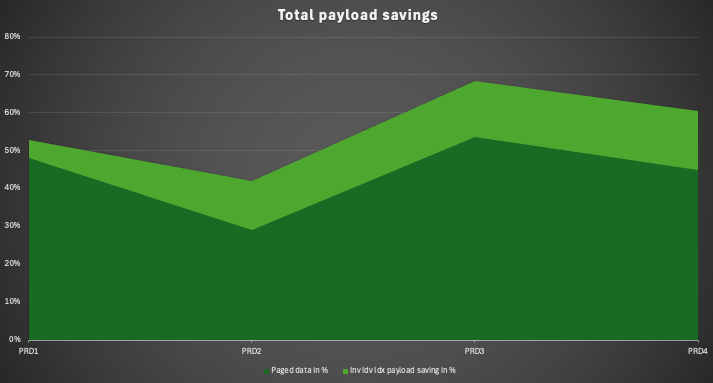
Both data tiering methods, NSE and Inv Idv Idx, can cut your sizing more than half. In our customer case we observed payload savings of 42% and 69%. This means it is depending on the performance. Within the current times the needed resources can be quite expensive. These two aspects of data tiering are the most weighted once. Comparing the costs of a data tiering projects and the savings it is fast ROI calculation. The point in time of such a project can be quite important. For instance, the procurement of new hardware or the migration to the cloud or beginning a RISE journey. It can save immense costs if such a project can cut the sizing before such contracts are signed.
SAP HANA News by XLC