HANA News Blog
HANA Sequences - the hidden handbrake in the system
Usage of Sequences
Do you use sequences in your SAP HANA systems? This should definitely be checked. If not set up correctly, these can have a major impact on the performance of individual SQL statements. A HANA sequence can be compared with a consecutive number range in ABAP. The sequence generates unique, preceding numbers, which e.g. B. can be used by a HANA trigger or when INSERT into a table. Similar to ABAP, numbers can be buffered. By default, however, the cache is set to 1.
If many operations access the sequence at the same time, there is a waiting situation until the next number is assigned. This problem can be solved by increasing the sequence cache. Note: There may be gaps in the assignment due to the use of the cache, but the numbers are always consecutive.
How do I check whether developers or even third-party vendors are using HANA sequences?
Recognize sequences in statements:
The sequence can be recognized in the statement by the “.NEXTVAL” function.

Example with triggers:
The trigger, which in turn uses a sequence, accounts for about 90% of the statement's runtime. Seen here in the context of the child processes.

Kernel Profiler
Statement Collector of the trigger statement
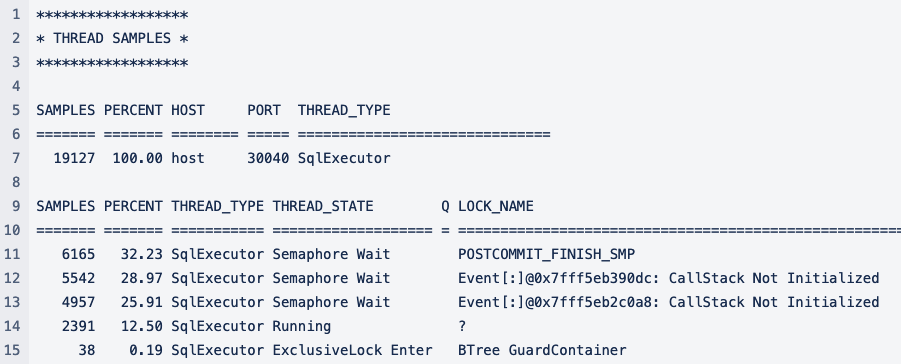
CallStack Not Initialized
: This is a generic, unspecific semaphore name used for various semaphores in IBM on Power environments. On Intel they follow the naming convention "<module>.cpp: <function>" instead, e.g. "DeltaIndexManager.cpp: TRexAPI::DeltaIndexManager::MergeAttributeThread::MergeAttributeThread".
The Kernel Profiler can be used to determine exactly what the DB is doing in this status. This also applies to other cases.

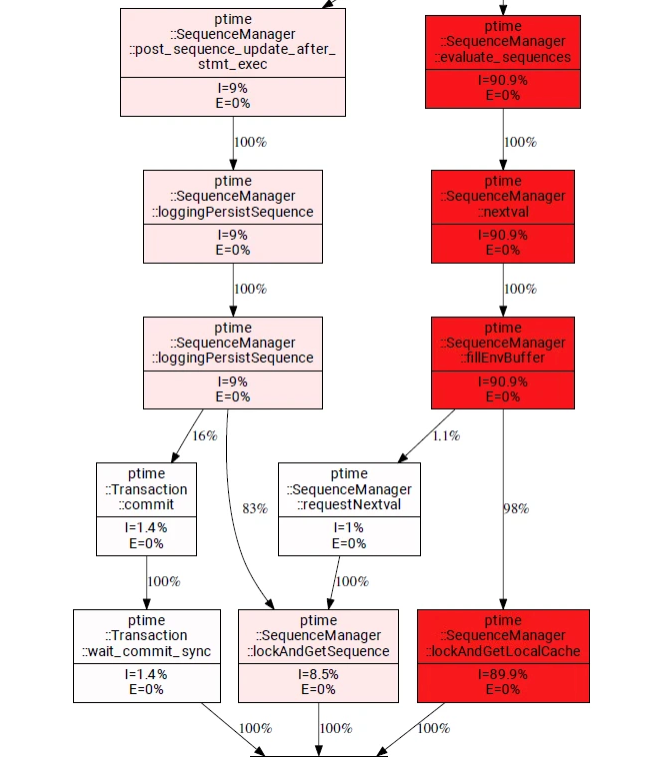
3,88s waiting
The HANA sequence accounts for over 90% of this
In the specific customer case, this had the following effect:
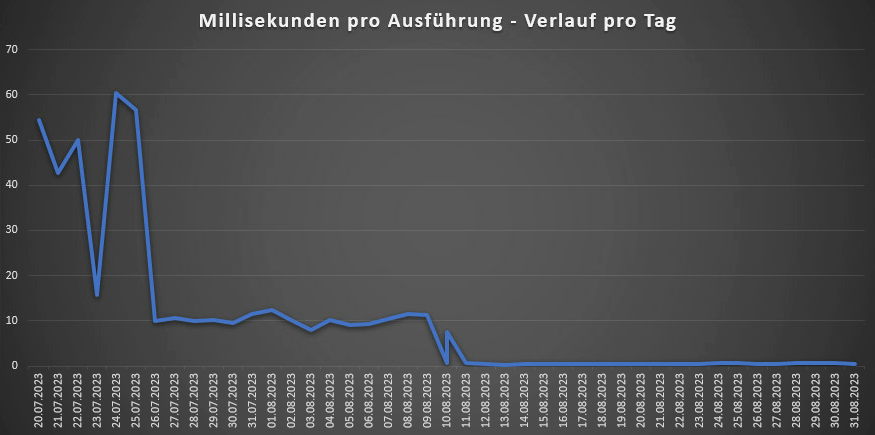
Peak times before caching: 160ms per execution
Peak times after caching: 1ms per execution
The daily average is as follows:
SAP HANA News by XLC