HANA News Blog
NSE - wrong buffer cache sizing
Urgent recommendation: monitor your buffer cache


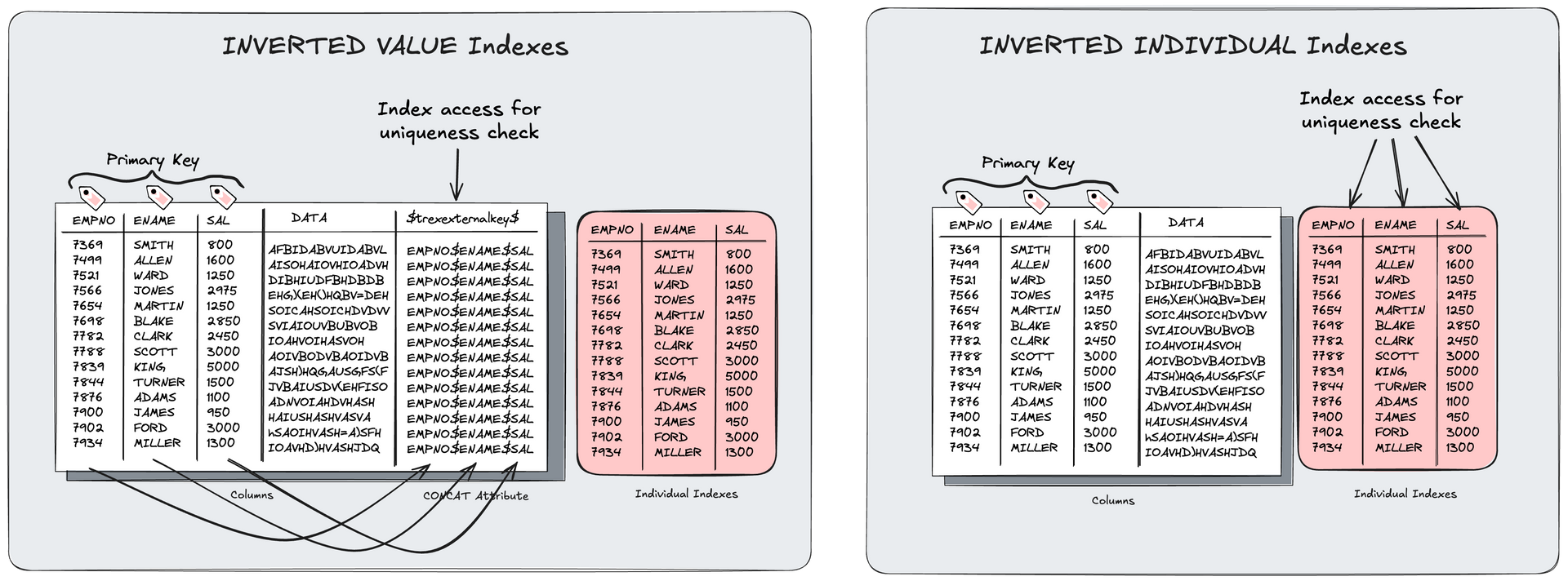
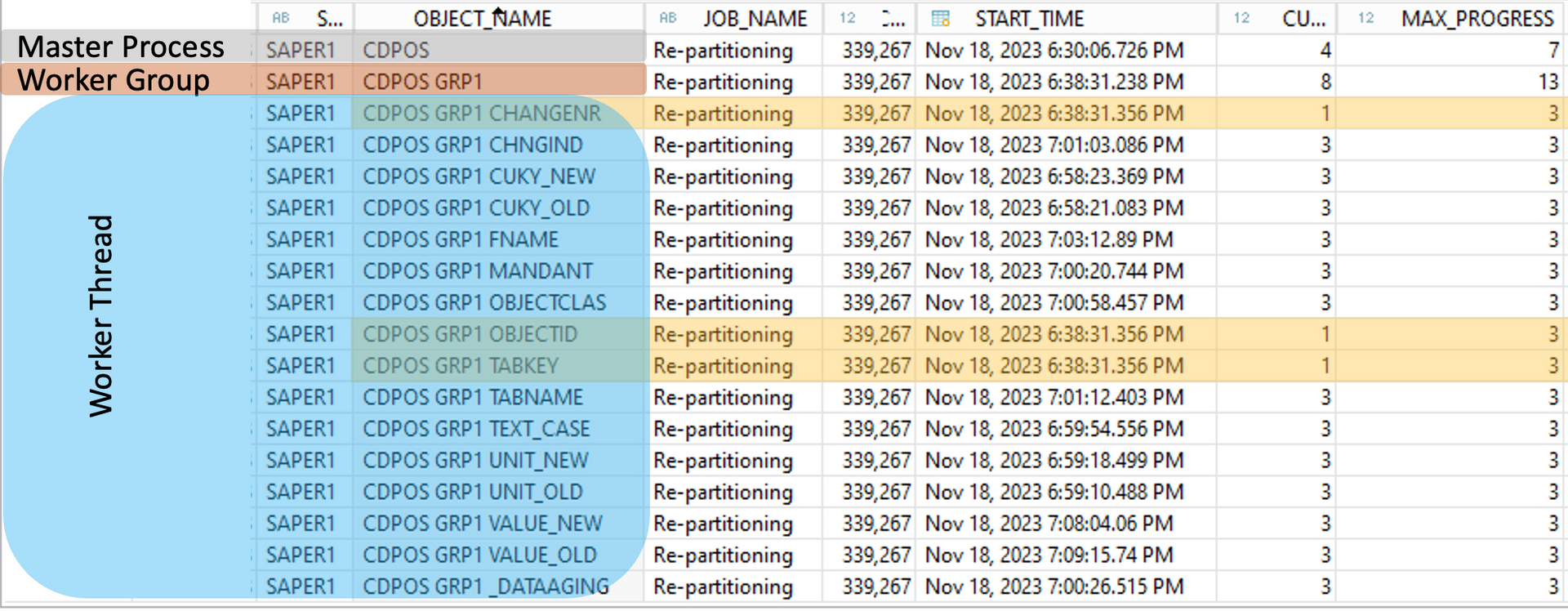
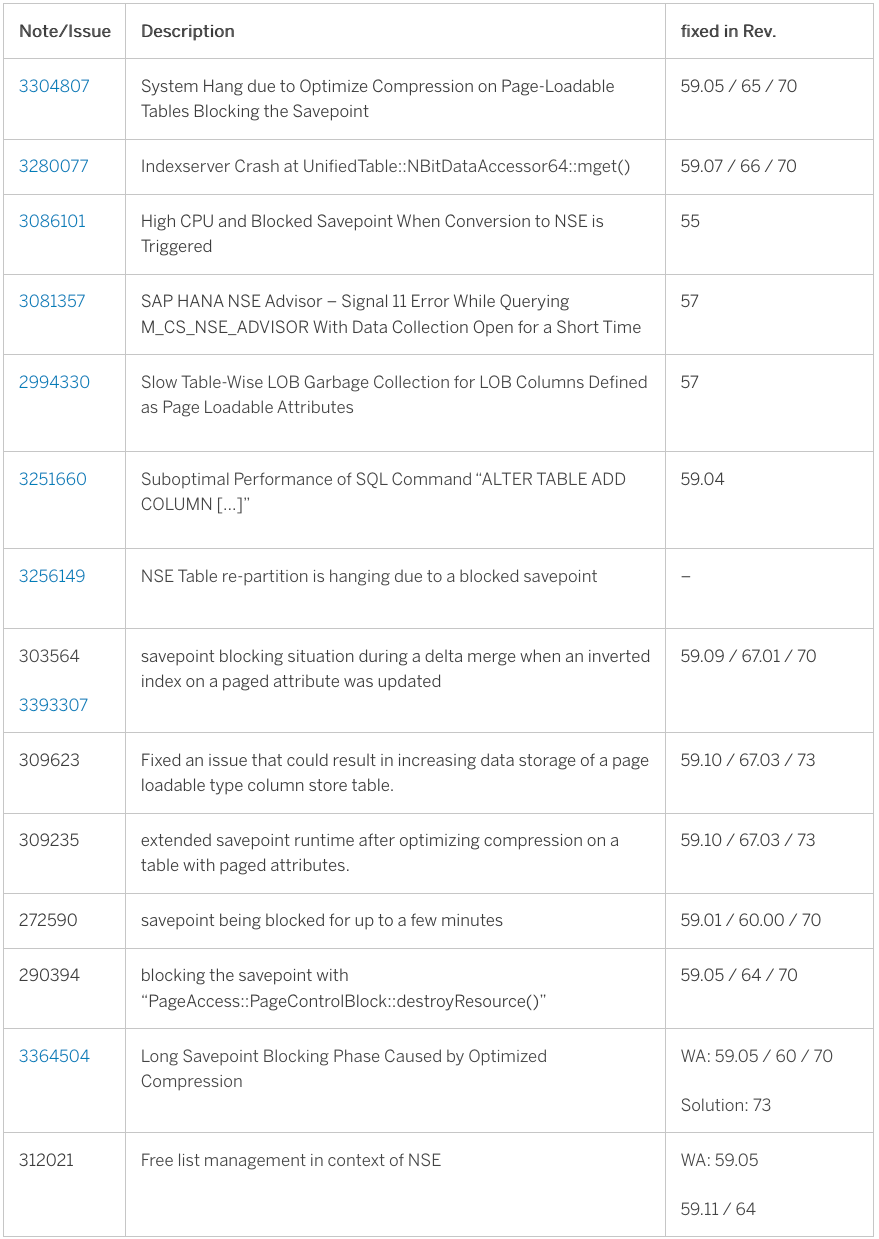
If you are not monitoring your buffer cache (=BC) over your landscape when you are using NSE, you can get serious problems. If the BC is too big, you waste memory and the saving rate drops. This is no big deal but should be avoided. The other way around - the BC is too small - will create some trouble. With every merge, optimize compression or CC (=consistency check) all components of the table will be loaded into memory. This means the BC must be big enough. Not big enough for the entire table, but big enough for the biggest column of a table/partition. In all other cases the CCL (ConsistentChangeLock) will be locked for a long time. This can cause issues for savepoints. There are already a lot of issues regarding NSE and such situations (see picture below).
With SAP HANA 2.00.059.05 - 2.00.059.10 the following parameter can be set to improve the situation by avoiding unnecessary buffer allocations and deallocations (issue number 290394):
indexserver.ini -> [buffer_cache_cs] -> async_prealloc_in_chunks_enabled = false
With SAP HANA >= 2.00.059.11 and >= 2.00.064 this parameter is set to false per default (issue numbers 290394, 312021).
Together with our partner solid cloud we are developing monitoring custom check with Avantra to fill the gap of other monitoring solutions.
We try to keep track on them in this blog:
SAP HANA News by XLC