HANA News Blog
SUM tooling with target HANA
SUM tooling: what is currently not covered for big tables
"The SUM tool will do all the work and guide us, when something is missing"
- true or false?
Numerous IT projects such as S/4HANA projects or HANA migrations will go live over the Easter weekend. Mostly this tasks will be controlled by the SAP provided SUM tool. The SUM is responsible for the techn. migration/conversion part of the data. Over the past years it become very stable and as long as you face no new issues nearly every technical oriented employee at SAP basis team can successfully migrate also bigger systems. In former times you needed a migrateur with certification which is no longer required. As long as all data could be migrated and the system is up and running the project was successful. But what does the result look like? Is it configured according to the best recommendation and experience? Is it running optimized and tuned?No, this is where the problem begins for most companies. The definition of the project milestone is not orienting on KPIs. It is simply based on the last dialog of the SUM tool, which states that the downtime has ended and all tasks have been executed successfully.

Neuer Text
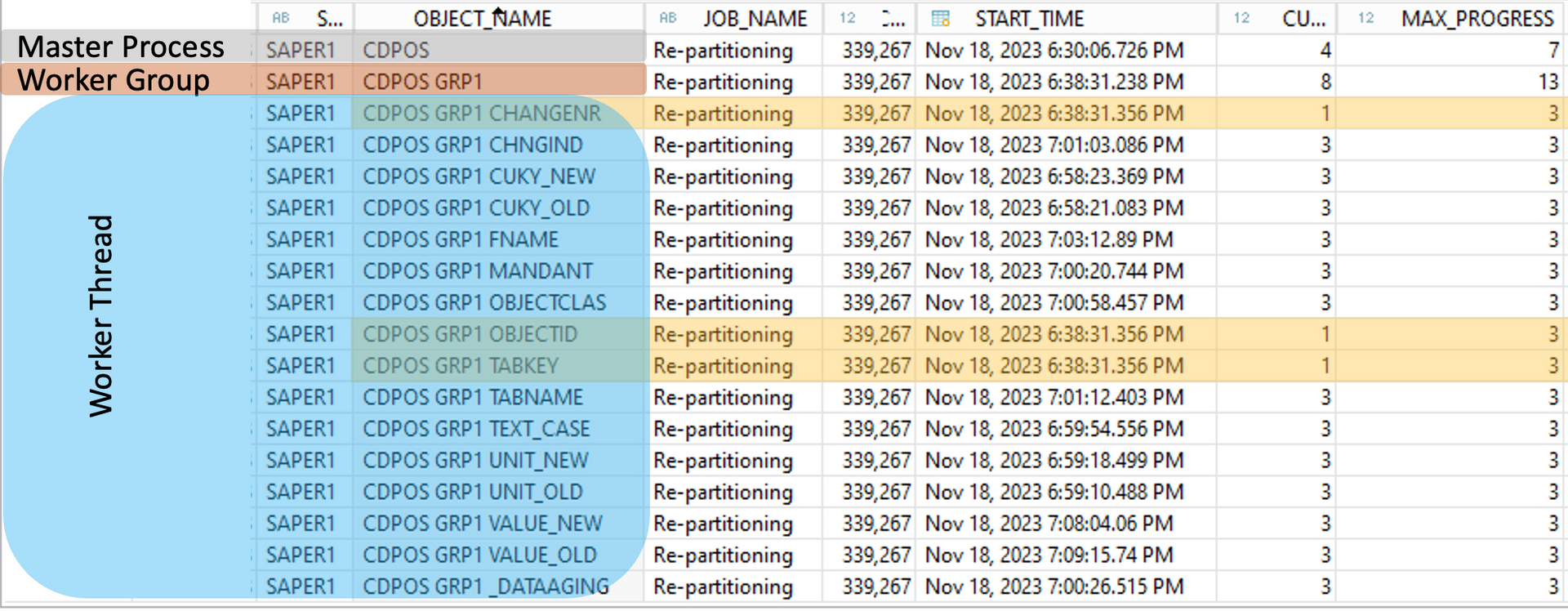
1. HANA DB - the final table structures after SUM handling
If you look at your final HANA database, you will also see some partitioned tables. The most customers think 'perfect SUM has taken care also of my partition design'. Since years I see worse partition design due to the handling of SWPM and SUM. The target of this tools is just a fitting structure bypassing the 2 bln records limitation. This means only a few tables like CDPOS or EDID4 will get a proper HASH design on a single column. This means the selection of partition design is appropriate but may be not the number of partitions. The growth is not considered.
2. Wrong partition design
The rule for most of the other tables is if the table has more records than 1 bln per table/partition partition it by the primary key (PK). The partitioning by PK will always achieve a working structure, but is it recommended to use it as partitioning attribute? No! Especially in the context of performance it is horrible to use the PK. Partition pruning and NSE can not or only partly be used on this tables depending on the query (regarding pruning).

3. Missing partitionings?
Are all tables partitioned by SUM which should be partitioned? Also here the answer is no! There are some golden rules on the HANA database how big partitions should be created at the beginning. The partition size should be min. 100 million and max. 500million records. The SUM splits as soon as you reach 1 bln records. This means also that in the worst case if you have 1.99 bln records, you have nearly 1 bln per partition and if SAP is not delivering a partition design you will end up with PK and 1 bln records per partition. Even worse if the number of records are low but the size of the table is high due to VARBINARY or huge NVARCHAR columns or also a high number of columns/fields. Best examples are CDPOS [huge NVARCHAR columns], BSEG (404 columns), VBRP (282) [high number of fields], BALDAT and SWWCNTP0 [VARBINARY]. Very large tables also result in long delta merge and optimization compression run times, which should be avoided. Additionally, there is limited ability to parallelize filtering in queries. Inserts can be accelerated by multiple partitions as they are performed by column and per partition. An ideal size is 15-30GB. If a delta merge takes several times longer than 300s it can be an indication that is table should be partitioned.


In the end SUM is a perfect tool which should be used, but you still have to check notes and guides. Even if the result is a running HANA including all data, you still have to ask questions about scalability and performance. SUM is the tool for migrating/converting the data and not for operating it optimally. Please take care of this aspects and create milestones / define KPIs in your project to check also this aspects. You should consider a techn. QA instance or health checks for your systems. Ideally before go-live, this saves time for re-partitioning. But even if you encounter problems after going live, you can adjust the design. We already guided several projects and discovered wrong partition design, parameters, missing indexes and many more. We can write a book about all this discoveries - wait we already writing one ;)
How you can do a fast check if your system should be checked (tables > 800.000.000 records and 30GB):
select TABLE_NAME, PART_ID, TO_DECIMAL(MEMORY_SIZE_IN_TOTAL/1024/1024/1024 , 10, 2) MEMORY_SIZE_IN_TOTAL_IN_GB, RECORD_COUNT from M_CS_tables where RECORD_COUNT > '800000000' OR MEMORY_SIZE_IN_TOTAL > '30000000000' order by MEMORY_SIZE_IN_TOTAL desc;

SAP HANA News by XLC