HANA News Blog
Dynamic Range Partitioning - Threshold Option
Dynamic range partitioning
With RANGE partitioning (like mentioned in the blog series), the data is divided into individual sections based on one or more characteristics. This allows you to determine exactly which data should be written to a partition. The most common use cases here are partitioning based on time or number values. In order to be able to determine the optimal size and, above all, the characteristics, in-depth application knowledge is required. Collaboration with the relevant specialist department is usually essential.
If partitioning is set up according to RANGE, regular maintenance must take place (e.g. definition of new partitions for the coming year for time-based areas, deletion of old partitions after archiving).
The big advantage is the flexibility and scalability with RANGE. Even if one range is not fitting your requirement any more you can just repartition the affected partitions. There is no need to repartition all data of the table. Only the required data / partitions will be touched. But this applies only for the standard (offline) option. The online option will always redistribute all the data.
Design
Range partitionings should always include an additional partition called OTHERS. This partition has no range definition and is the landing zone for records which cannot be assigned to a defined range partition. If a lot of records are saved into an OTHERS partition you should create a range for this data records or check what is going wrong. This means also proper monitoring is an important task when using partitioning.
When you create an OTHERS partition there is a risk that over time it could overflow and require further maintenance. Using the dynamic range feature the others partition is monitored by a background job and will be automatically split into an additional range partition when it reaches a predefined size threshold.
There are automatisms in place which called dynamic range partitioning.
Pitfalls RANGE partitioning
Since RANGE partitioning can be significantly more complex than HASH partitioning, there are also more pitfalls to consider. It may not be distributed evenly like for HASH designs. You are responsible to design it along the rules of partitioning.
You have to analyze the data quality of your partition attribute. If you just use a time attribute because it is the only one means not that it is the only way. If the attribute is not used in your queries you may will end up in a bad performance for this table, because no pruning can be used.
All additional options regarding dyn. range partitioning have certain limitations and besides benefits also some negativ impacts if you have not analyzed and monitored them well.
Threshold option
Tables with a dynamic others partition are monitored by a configurable background job which checks the current size of the partition in comparison to the defined limit and makes adjustments as required. If the OTHERS partition has exceeded the defined limit then all records in the OTHERS partition at the time the job runs are added to the new partition, the corresponding SQL statement is ADD PARTITION FROM OTHERS.
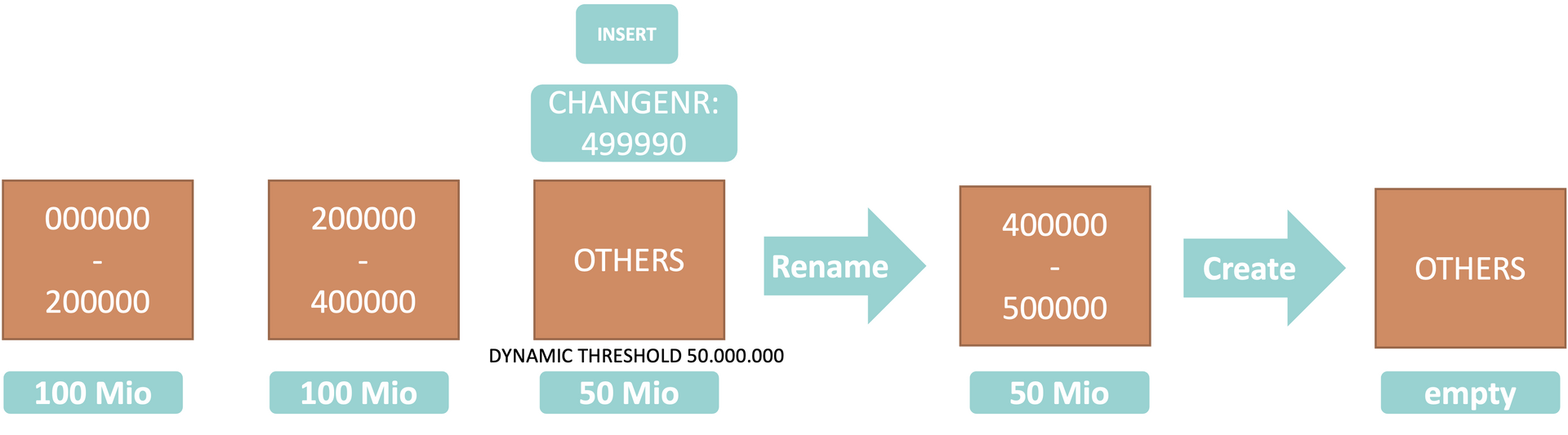
If you define a dyn. threshold of 50 Mio, a new range will be created with the min. value and the max. of the OTHERS partition.
You have defined ranges from 0 to 400,000. If you insert rows above the value 400,000 for CHANGENR they will be saved to the others partition. If the record count of the OTHERS partition (NOT the value of CHANGENR) will reach 50,000,000 a range will be created with the min value 400,000 and may be an odd number like 500,042 but again to illustrate it simple 500,000. A new empty OTHERS partition will be created for new entries without valid range as safe harbor.
It still can happen that a range can run full due to heavy usage of a certain number. This means multiple records of a CHANGENR. In this case, you still need to repartition your table and can adjust the threshold to a lower value.
Usage
This means this option can be useful if you are not aware of the min. / max. values of a partition and the only indicator is the records length and thus the partition size which leads to a certain number of records per partition.
Syntax
ALTER TABLE T ALTER PARTITION OTHERS DYNAMIC THRESHOLD 300000000;
Parameters
Partition parameters [partitioning] section of indexserver.ini :
dynamic_range_default_threshold (Default = 10000000)
dynamic_range_check_time_interval_sec (Default = 900s)
How you can check if threshold option is active?
SELECT TABLE_NAME, DYNAMIC_RANGE_THRESHOLD from TABLE_PARTITIONS
Pitfalls Threshold Option
Using the THRESHOLD property empty partitions are also removed during this process.
The creation of a new partition automatically stops the growing of existing partitions. You have to find out the right number of records for the threshold. This can be 300,000,000 records but this can also only 50,000,000 it depends on the scenario and usage of the table. It can also change over time due to higher workload. A proper monitoring is essentially for using RANGE partitioning. Do you have such a monitoring in place which monitors empty partitions, size of partitions, number of records per partition etc.? No? Let's get in touch to avoid unwanted situations (bad performance, error due to 2 billion records, right partition design, right threshold values etc.).
SAP HANA News by XLC