HANA News Blog
BW data tiering - a success story
Efficiently managing data for better performance and lower total costs

A few years ago, you often heard the phrase “data is the new oil”. Well this may be one of the reasons the BW systems are growing so fast. Since years there a possibilities with BW on anyDB and BWoH to save ressources with NLS. But for some scenarios this is not suitable in terms of performance or design. The challenge: Stop the growing and needed resizing of a already out of sizing BW/4HANA system of already 24TB (Scale-up). For additional optimization besides NLS, we analyzed the system and found more than just one product or feature could solve.
We found aspects which we see mostly in systems: a grown data model over several years. But we found ways to optimize:
- Removed overhead in key attributes which reduced the PK size (often more than 50% of the overall table size)
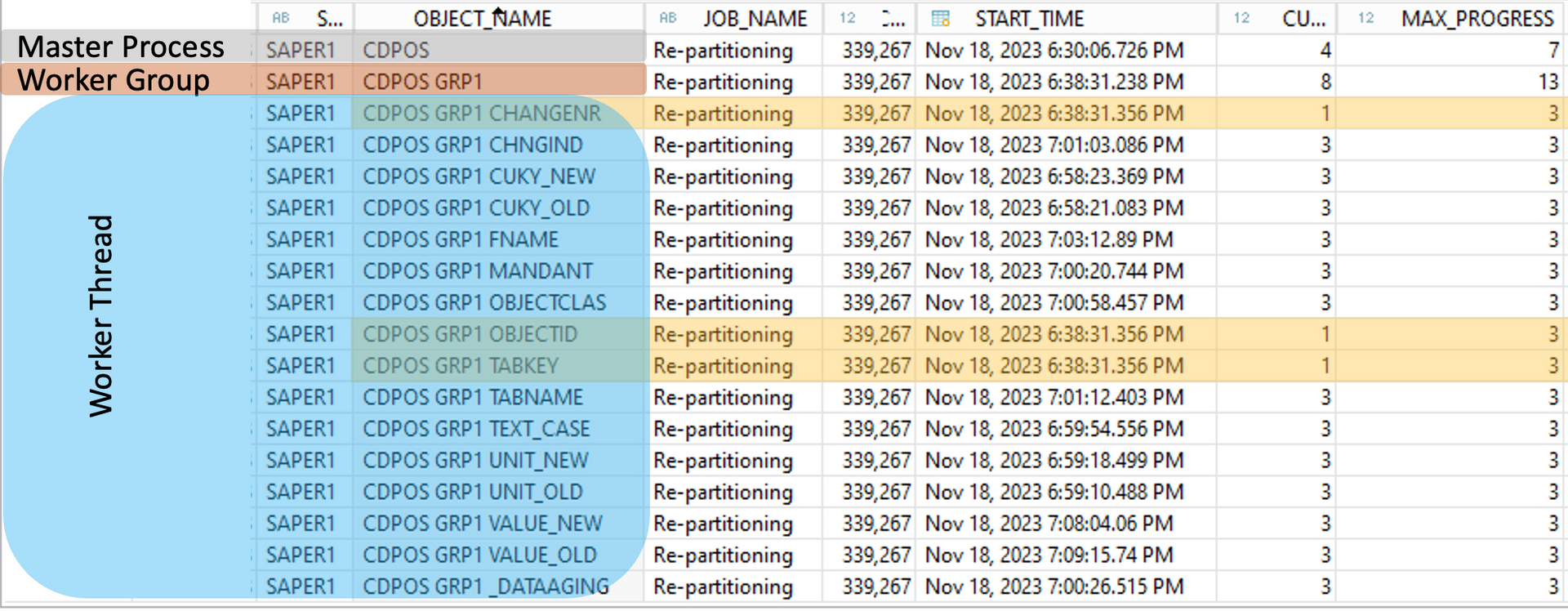
- optimized the partitioning design
- used NSE for write optimized ADSOs
- introduced NSE for several ADSOs
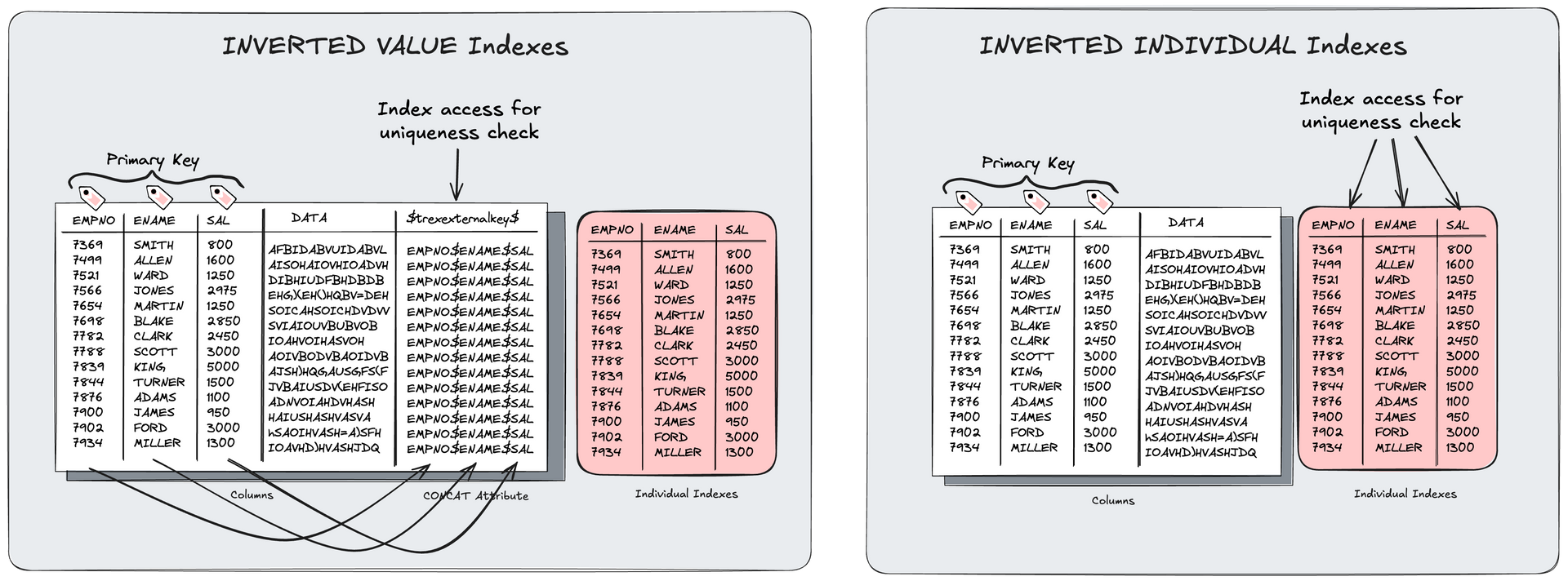
- optimized usage of inverted individual indexes
We saved over 800GB just with removing unnecessary key attributes.
With an optimized partitioning strategy and the new possibilities of BW/4HANA we could reduce the meta data overhead in the dictionary which also saved over 500GB in total.
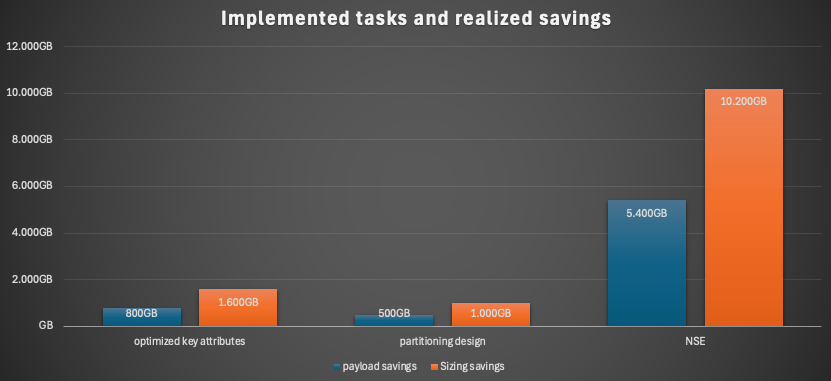
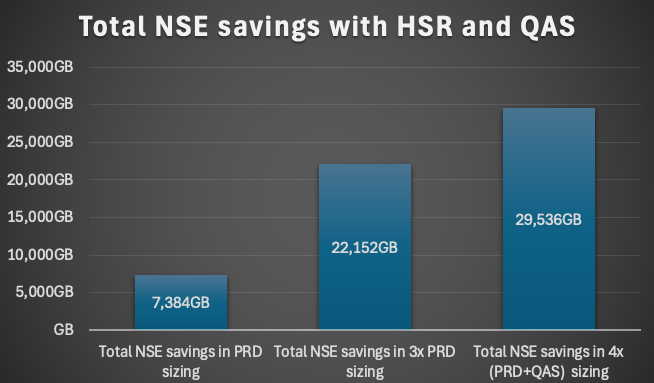
The introduction of NSE was the real game changer which saved more as we estimated. The estimation was round about to page out 4TB. In the end we paged out 5,4TB which results in terms of sizing in round about 10TB savings (some memory for the buffer cache must be counted in).
The journey is not over yet, we still have some ADSOs not covered and calculate with additional 1TB to be paged out. On top we are working on another possibility to convert the current inverted hash indexes to inverted value and save another 1,5 - 2TB of memory.
A great team effort which could only be achieved when BW team and DBAs working close together. The target of saving 8TB was exceeded.
SAP HANA News by XLC